- Data Hackers Newsletter
- Posts
- Como criar uma árvore de decisão em Python: um guia prático
Como criar uma árvore de decisão em Python: um guia prático
Aprenda passo a passo a construir uma árvore de decisão em Python utilizando bibliotecas populares como scikit-learn.
Data Hackers
February 25, 2025 • Tempo de leitura estimado: 8 minutos
Você sabia que as árvores de decisão podem revolucionar a forma como você toma decisões baseadas em dados? Neste guia prático, vamos explorar passo a passo como construir uma árvore de decisão em Python utilizando a popular biblioteca scikit-learn. Com essa ferramenta poderosa, você será capaz de automatizar processos, otimizar previsões e impulsionar decisões estratégicas em diversos contextos, como negócios, saúde e finanças.
A estrutura de uma árvore de decisão simula o raciocínio humano, permitindo visualizar as decisões e os resultados de forma clara e intuitiva. Ao longo deste post, você aprenderá desde a preparação dos dados até a execução de previsões, entendendo inclusive como esse modelo se adapta à classificação e à regressão, o que o torna uma escolha valiosa para analistas e cientistas de dados.
O que é uma árvore de decisão?
Uma árvore de decisão é uma estrutura de aprendizado utilizada em machine learning que simula o raciocínio humano para automatizar funções e decisões em softwares e aplicativos. Esse modelo se baseia em uma estrutura que tem forma visual semelhante à de uma árvore, e leva decisões e resultados a serem alcançados por meio de etapas bem definidas.
Essa chamada árvore começa com uma raiz principal que se ramifica em troncos, nós e folhas. Cada um desses elementos representa resultados potenciais gerados a partir dos dados iniciais, permitindo à máquina "pensar" de maneira organizada e estruturada. As árvores de decisão são particularmente valiosas para a automação de processos em empresas, pois possibilitam previsões, cálculos de riscos e a análise de múltiplas variáveis de forma intuitiva. Essa característica torna este método acessível até mesmo para profissionais que não possuem um conhecimento técnico aprofundado em dados.
Além disso, as árvores de decisão são frequentemente usadas em classificação e regressão, oferecendo uma versatilidade que as torna populares em diversas aplicações.
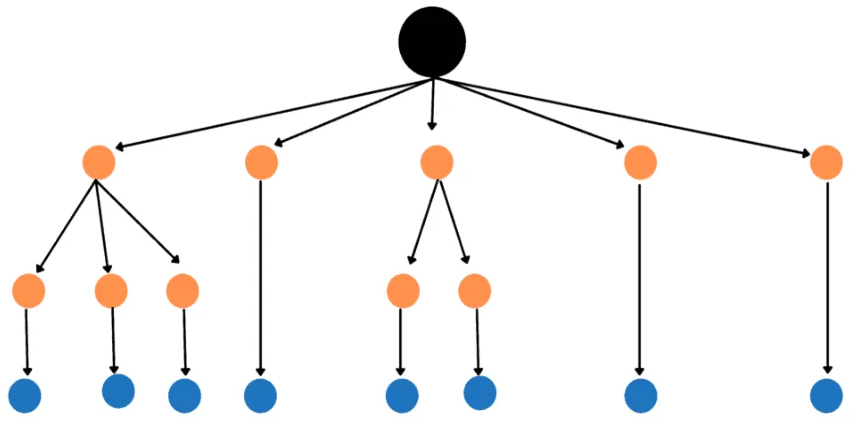
Esquema de uma árvore de decisão
Para que serve a árvore de decisão?
As árvores de decisão são amplamente aplicadas em machine learning para realizar classificação e regressão. Elas preveem categorias discretas, como "sim" ou "não", além de valores numéricos, como o valor de lucro de um produto. A popularidade das árvores de decisão provém de sua versatilidade e de sua eficácia em problemas que envolvem múltiplos rótulos.
Outro ponto importante é sua facilidade de uso em relação ao tratamento de dados, pois essas árvores podem lidar com valores atípicos e dados faltantes sem comprometer significativamente seu desempenho. Especialmente em cenários onde a qualidade dos dados pode variar, isso as torna uma escolha favorável.
A combinação de árvores de decisão em uma random forest (floresta aleatória) é comum, combinando um conjunto de árvores treinadas para assim realizar predições com maior precisão e robustez.
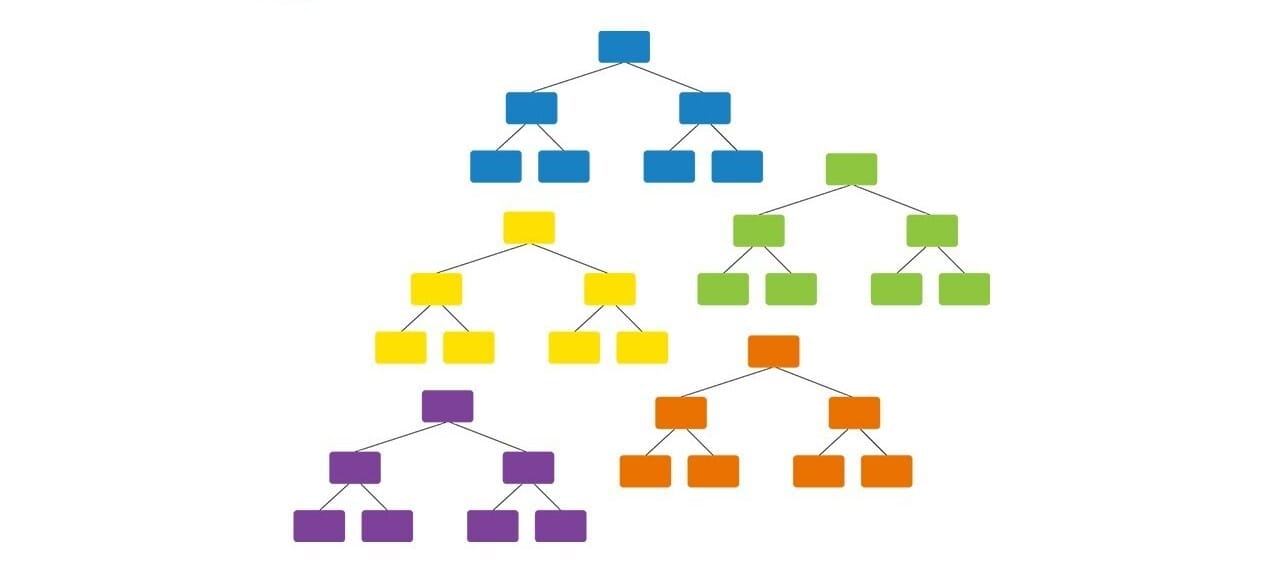
Uma chamada ramdom forest (floresta aleatória)
Como elaborar uma árvore de decisão em Python?
Para elaborar uma árvore de decisão em Python, siga os passos descritos abaixo, usando a biblioteca scikit-learn. Aqui está um guia resumido:
Passo 1: Importar bibliotecas necessárias
Utilize Pandas para manipulação de dados, Matplotlib para visualização e sklearn para a construção do modelo de árvore de decisão. Você pode importá-las usando os comandos abaixo:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
Passo 2: Importar o dataset
Selecione e importe o dataset que será utilizado. Como exemplo, um conjunto de dados que contém informações sobre condições climáticas:
dataset = pd.read_csv('seu_dataset.csv')
Passo 3: Preparar os dados
Transforme colunas relevantes em variáveis dummy (utilizando get_dummies() do Pandas) e mantenha a variável alvo categórica:
dataset = pd.get_dummies(dataset, columns=['clima', 'temperatura', 'umidade', 'vento'], drop_first=True)
X = dataset.drop('jogar', axis=1) # variáveis independentes
y = dataset['jogar'] # variável dependente
Passo 4: Construir a árvore de decisão
Use a classe DecisionTreeClassifier do scikit-learn para treinar o modelo, adicionando um limite de profundidade para evitar o overfitting:
model = DecisionTreeClassifier(max_depth=3)
model.fit(X, y)
Passo 5: Visualizar a árvore de decisão
Após o treinamento, visualize a árvore para entender como as decisões são tomadas:
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(model, filled=True)
plt.show()
Passo 6: Fazer predições
Utilize o modelo treinado para fazer previsões em novos dados:
predictions = model.predict(novos_dados)
Seguindo esses passos, você terá uma árvore de decisão construída e poderá usá-la para fazer previsões com base nos dados de treinamento.
Diferenças entre árvores de decisão para classificação e regressão
As árvores de decisão são modelos versáteis, utilizados tanto para classificação quanto para regressão. Aqui estão algumas diferenças fundamentais:
1. Objetivo
Classificação: O objetivo é classificar dados em categorias discretas (ex: “aprovado” ou “reprovado”).
Regressão: O foco está em prever um valor contínuo, como o preço de um imóvel com base em características.
2. Tipo de saída
Classificação: Saída categórica (uma classe ou rótulo).
Regressão: Saída numérica contínua.
3. Critério de divisão
Classificação: Utiliza métricas como impureza de Gini ou ganho de informação para verificar a qualidade das divisões.
Regressão: Baseia-se na minimização da variância ou do erro quadrático médio (MSE).
4. Interpretação dos resultados
Classificação: Resultados interpretados em termos das classes previstas e a confiança na previsão.
Regressão: Representa a previsão de um valor específico da variável dependente.
Exemplos práticos de uso da árvore de decisão em Python
As árvores de decisão podem ser aplicadas em uma variedade de cenários. Aqui estão alguns exemplos práticos:
Diagnóstico de doenças: Treinadas com dados de pacientes, elas podem prever condições de saúde como diabetes.
Previsão de empréstimos: Analisam dados financeiros para determinar a concessão de um empréstimo.
Análise de sentimentos: Classificam sentimentos expressos em textos como avaliações de produtos, por exemplo.
Previsão de saída de funcionários: Avaliam a probabilidade de um determinado funcionário deixar a empresa.
Pontuação de crédito: Classificam clientes em relação à probabilidade de pagamento de um empréstimo.
Segmentação de clientes: Identificam grupos de clientes que têm maior probabilidade de compra.
Modelo de clima para jogar golfe: Aplicam a árvore de decisão para prever condições climáticas favoráveis para a prática do golfe.
Esses exemplos demonstram como as árvores de decisão são ferramentas valiosas na tomada de decisões informadas e baseadas em dados.
Finalizando
Ao final deste guia, você se familiarizou com o processo de construção de uma árvore de decisão em Python utilizando a biblioteca scikit-learn. Discutimos desde a importância desse modelo para a tomada de decisões até a prática de construção e visualização da árvore, permitindo que você compreenda melhor como as previsões são feitas com base nos dados.
Com o conhecimento adquirido, você pode agora aplicar árvores de decisão em diversas áreas, como negócios e saúde, otimizando suas análises e automatizando processos. As possibilidades são muitas, e a prática contínua com esses modelos será a chave para se tornar um especialista e explorar todo seu potencial.